Down the Rabbit Hole of Genetic Genealogy
I came to this investigation of my ancestors as a complete novice in the areas of genealogy and genetics. Now after a few months of study and effort, I am better informed—although still not an expert. Fortunately, there are services available to help which are at the same time accessible and powerful. The two that I have most successfully employed are 23andMe.com and Ancestry.com. These applications are complementary and provide slightly different information at a modest price (approximately $100 for the basic DNA analysis).
The former (23andMe) is focused primarily on health and general ancestral origins with only a few tools for genealogical research. Nevertheless, I was able to identify common ancestors with many individuals with their gracious help. In particular, I was able to identify specific genetic markers that suggest an Estimated Recent Shared Ancestor (ERSAs) among various subgroups of the nearly 1500 individuals (in each application) with whom I share significant lengths of DNA. Likewise using Ancestry.com, I identified relatives near and distant whose existence has helped answer genealogical questions that have been mysteries for decades. But more about that later. First I must provide a simple primer on the essentials of genetic science for a general audience. If readers are already familiar with the topic he or she may wish to skip ahead to the subsequent sections. But they will miss the fun of what I have learned in recent days.
How We Become Who We Are
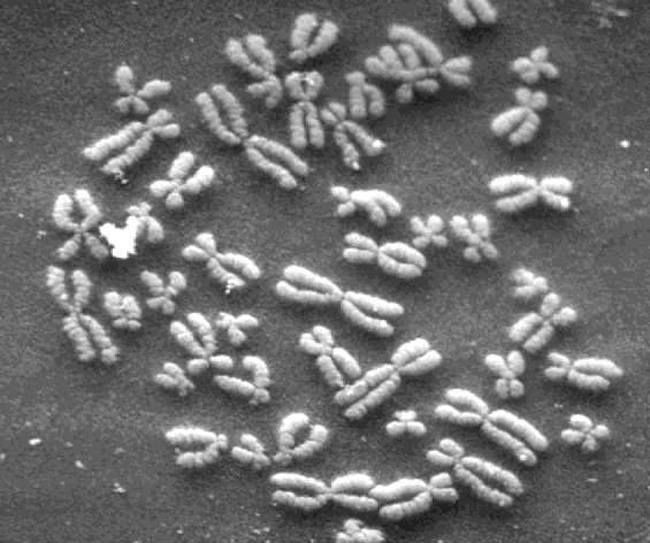
I, like most folk, came to the topic of genetics with a vague appreciation that the “blueprint” of how to assemble a human is stored in the genetic molecule DNA (DeoxyriboNucleic Acid). What I did not appreciate is how this very long double helical molecule (approximately two meters long if unraveled) is managed and stuffed into a tiny cell by the machinery of life. I learned that the DNA of humans is divided into 46 separate bundles bound up in 23 pairs. These pieces are the chromosomes. In the micrograph above we can see the image of some chromosomes. They are of different lengths and are “diploid,” that is, they exist in pairs that are held together at a point on their length so that they resemble microscopic “exes.”
Humans are eukaryotic creatures; that is, all their DNA is lumped in pieces of various length inside the nuclei of their cells. More specifically, the nuclei of human cells contain 22 so-called autosomal chromosome pairs (numbered 1 to 22), and one pair of sex chromatids (designated X and Y and normally paired XX in females or XY in males). In the process of producing offspring, the gametes—the sperm and ovum—combine to pass on DNA derived from the parents. The 22 autosomal chromosomes and the sex chromosome are thus a 50%-50% combination of DNA derived from Mom and from Dad.
The process must be a little more complicated than this, of course, or there would be an accumulation of genetic material in each successive generation. In a process called meiosis, the chromosome pairs split in half before the formation of each “haploid” gamete, containing half the number of chromosomes of the normal cell. Thus, only half of the genetic material from each parent is inserted, respectively, into the sperm or ovum and then passed down to the next generation in the fertilized zygote. Problem solved.
But wait, there’s more—of course. Prior to meiosis the paired chromatids (that originated in the generation of the grandparents, the respective parents of mother and father) have undergone a mixing process called recombination by crossover. While the autosomal chromatids are still joined by a bundle of fibers called the centromere, the chromosomes in Mom and in Dad, prior to conception and prior to meiosis, can do some microscopic genetic acrobatics and flip to the other half so that when the chromosome ultimately splits into two halves, the genetic information becomes a mixture of the previous generation.
Ultimately the fertilized zygote will inherit half of its DNA from father and half from mother. Therefore, in the foregoing marvelous mechanism of biological engineering a mixture of traits inherited by our parents from their parents (our grandparents) gets passed on to us in a fleshly lottery. Because of the random sorting we share about (but rarely exactly) 25% of our DNA with each of our four grandparents and 50% of our parental DNA. On average the contribution to our genetic identity from each ancestor is diluted by a factor about ½ in each generation. This kind of delightful combinatorics arithmetic delights my physicist’s mind but leaves most folk cold. Considering a graphic representation (see figure 2) however may help communicate the beauty of this reality.

Suffice it to say that we can estimate (with increasing uncertainty the more distant the relation) the relatedness of two individuals just from the amount of DNA that they share (See a plot of the experimentally determined fraction of shared DNA in unique segments as derived from the Shared CM Project, https://dnapainter.com/tools/sharedcmv4. Check out a detailed explanation at https://www.familysearch.org/blog/en/centimorgan-chart-understanding-dna/ ). The fewer the generations since we have a common ERSA (Estimated Recent Shared Ancestor) the greater will be (on average) the amount of our shared DNA.

A logarithmic plot of the experimentally-determined fraction of the unique 6800 cM (or 7400 cM in some analyses) segments of DNA that are shared between related individuals. (A cM or centiMorgan is a measure of the length of shared DNA.). The Degree of Relatedness is computed by counting up a family tree to the ERSA (Estimated Recent Shared Ancestor) and then down to the relative. If there are two common ancestors the degree is reduced by one. Thus, half third cousins (who share a single 2x great-grandparent) have a degree of relatedness of 8, four generations each to the ERSA. These half third cousins (½ -3C), on average, share about 0.7% or about 48 cM of their DNA. The amount can vary, however, from zero to over twice that amount.
I should point out that all humans share 99.9% of the same DNA, that is, we are 1000 times more alike than we are different. In contrast consider that our most closely related primate cousins, chimpanzees and bonobos, each share only 98.7% of the base pair sequences (the amino acids abbreviated ATGC, for adenine, thymine, cytosine, and guanine) found in humans, albeit the apes have 24 chromosome pairs, one more than humans. Even though we humans differ by such a minuscule fraction of the 3 billion base pairs in our personal genome, 30 million disparate bases pairs are sufficient to distinguish us and make us genetically uniquely individual.
A Little Practice in Genetic Genealogy
Population geneticists have identified DNA sequences that are characteristic of various people groups. These sequences permit classification of human DNA sample by what are called “haplogroups” and allow an admixture analysis. For example, I descend—via my paternal line running through Henry Matteson (1642) who immigrated to Rhode Island in about 1666—from a gentleman who lived in Europe about 10,000 years ago. The web site 23andMe informs me that one in about 140 of their male subscribers have this haplotype, namely R-L48.
Despite the relative commonality of this haplotype, I discovered a male relative whose surname differed from that shared by me and my brother (who also bears the R-L48 haplotype). Documentary genealogical research revealed, however, that my genetic cousin’s great grandfather changed his name during the Civil War from Tobias S. Matteson to the name of a disabled comrade of his Pennsylvania regiment, possibly to avoid being conscripted a second time after his discharge due to wounds. Tracing his pedigree back further uncovered that indeed my cousin is a descendant of the very same 7x great grandfather the patriarch Henry Matteson, called “The Immigrant.” Our families diverged about 360 years ago, but was exposed by a persistent genetic marker.
The combination of genetics and documentary genealogy is a powerful duo. In the interim since I last posted I have also helped my future son-in-law find the identity of his birth parents. While treasuring his deceased but beloved adoptive parents, he hoped to learn more about his physical heritage that he could share with his own biological children. In a relatively straightforward and surprisingly rapid investigation, I identified one of his DNA matches as a half-brother. Moreover, my son-in-law shared DNA with other descendants of a woman whose maiden name appeared on his birth record. By good fortune, another close match with a half-niece suggested the identity of his biological father. Using the method of genetic “triangulation” in which one identifies the individuals who share DNA segments with two other individuals we were able to build up a detailed family tree many generations deep. The code in Ancestry.com then matches up potential cousins from their crowd-shared family trees. In the process I was able to identify scores of living relatives and help him and his children connect with his previously unknown family. It was “straightforward” because the relationships were close. In contrast, in the case of our Miley investigation only third or fourth cousins who are independently descended from the mysterious 2x Great Grandfather Miley remain alive after about 180 years. We anticipate that we will share about 0.5% – 0.7% DNA with any surviving cousins.
The first issue we chose to address was the veracity of the family story that a “Miley” was James Marion Moates’ father. Of course, Rachel appears in the 1850 census next door to the Noah Moates family in Eucheanna, Florida and is listed as “Rachel Miley,” Head of Household. So the documentary evidence proves that she claimed Mr. Miley as her spouse, although no known record of a marriage exists. Originally, I submitted my sputum sample to 23andMe as did my brother and sister. Within a few months we had over a thousand DNA matches. Among those there were three whose last name was “Miley.” I contacted these individuals and with their help reconstructed their family trees back through sons of Robert David Miley (1762) and Elizabeth Goodman (1761) of Barnwell County, South Carolina. The closest relative of these was a descendant of William Goodman Miley (1812), an Alabama pioneer planter who lived down the road from the Moates clan in the period 1840-1847. The DNA match was consistent with a third cousin relationship, the sharing of a 2x great grandfather. Further genetic triangulation identified individuals who appear to share William Goodman Miley as an ERSA, consistent with his position as a 2x great grandfather of me and my siblings. What is more, over time I was able to identify over 100 other individuals who share Miley DNA who are not descended from the Moates line.
Therefore, the DNA evidence is compelling that my Great-great granddaddy is indeed a Miley-Goodman, a son of Robert and Elizabeth.
23andMe Miley Segment
What I learned from 23andMe was that I had inherited (presumably from my mother) a rather long segment of DNA on my 12th Chromosome that is shared by many descendants of Robert Miley (1762). In the figure below we see the segments shared by me and my siblings with a descendant of William Goodman Miley. One should note that my brother does not share the Chromosome 12 marker. In the genetic lottery he did not inherit this part of my grandfather’s Miley segment. This observation suggests that this present day and generation are our last best chance of solving the mystery of the Miley. Before the last few years accessible DNA analyses were unavailable. Moreover, the amount of DNA also becomes diluted in each successive generation and the difficulty of identifying relatives becomes more problematic. So the time is ripe for this study.

A partial map of the shared genealogically relevant DNA between a descendant TM (half third cousin one removed) of William Goodman Miley, her 2x great grandfather and me (Sam) and my siblings (Cindy and Dale). Note that we all share a short segment of chromosome 9 but my sister and I only have a marker on chromosome 12.
Not wanting to stake such a definitive claim on only one single DNA test, I also submitted a sample to AncestryDNA.com. The results were consistent with the 23andMe data. Among my matches were those of my aunt, my mother’s sister, granddaughter of James Marion Moates. Using the family tree builder in Ancestry.com I was able to confirm that nearly 200 DNA-matched individuals are descended from Robert Miley and Elizabeth Goodman and are thus third to fourth cousins. Over twenty of the cousins are directly descended from William Goodman Miley. In the next figure a so-called ancestry.com “Thruline” graphic shows seven of the children of Robert Miley (1762) and the number of identified matches in each line.

Therefore, the genetic genealogical results are unequivocal: I am descended from Robert Miley (as is my Aunt Ann Rowley). What is more, it is highly likely that my great grandfather is indeed William Goodman Miley.
Curiously, I have found no match in my DNA with any descendant of Samuel Miley or Robert Z, Miley, two contemporaries and neighbors of Rachel Moates Miley. While it is possible that the segment(s) that I (and my siblings) inherited from our mother’s Moates family was not inherited any of Sam or Bob Miley’s offspring, it strains credibility.

Conclusion
The DNA evidence is conclusive that the father of James Marion (Miley) Moates was a son of Robert Miley (1762) and was probably William Goodman Miley (1802).
In the next post we will pull together all the evidence to make a compelling case that William is my ancestor and we will attempt to reconstruct the events surrounding Grandfather Jim’s birth. Stay tuned.

[…] Tell Me Thy Name – Part the Third […]